本文共 3209 字,大约阅读时间需要 10 分钟。
Involution 个人理解
传统卷积具有 :
①空间不变性:卷积核共享。能有效地节省模型参数,且能维护平移的等变性。由于不能引入过多的参数,所以采用比较小的卷积核,但是小的卷积核(如3*3)不能获得广的感受野 (因此involution更容易检测出大物体)
② 通道特异性:能在不同的通道中包含不同的语义信息,在许多成功的深度神经网络上表现出比较多的冗余性
原本卷积核需要的参数数量 = C0(输入通道)×Ci(输出通道)×K×K
所以传统卷积比较难去得到长距离的感知,所以提出involution。
involution具有与传统卷积相反的:
①空间特异性:在不同位置上的卷积核是不同的。(kernel对应在一个空间位置上的参数值要与这个位置对应的输入特征向量相关(或者仅由其决定),incident可以自适应地为不同空间位置分配不同的权重)
②通道共享: 每一个组内的通道共享一个卷积核。这样还可以减少计算复杂度
involution卷积需要的参数数量 = H×W×K×K×G (H和W是什么?feature map的大小,因为每一个pixel都会产生G个卷积核,所以H×W是feature map的面积,即含有的像素点的个数。将1个像素通过全连接层和激活函数生成K×K×G个维度,通过reshape编程矩阵形式,再通过broadcast生成同样的一定深度,多个通道共享一个卷积核)
卷积核生成:
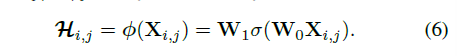
Xi,j代表位置(i,j)的特征向量。Wo和W1都是线性变换矩阵,前者可以使用1x1卷积用作压缩通道数,后者再将通道数扩展,类似于SE-Net的Sequeeze&Excitation过程。σ函数是BN和ReLU。而一个位置需要G个不同的卷积核,而应用conv2d卷积时,输出的shape最多只有4个维度,所以要把G和K×K参数放一起,最终输出的维度为(B,G×K×K,H,W)。最后要扩展多一个维度方便进行广播操作。
由于有了下述变换:Involution卷积比传统卷积的参数量要更少:第一层1×1卷积将通道从C压缩到C/r(r为压缩率),经过一个BN层和ReLu层后再由另一个1×1卷积扩张到G×K×K通道数。因此整个过程的参数量为:输入通道数×输出通道数×卷积核的大小为:1×1×C×C/r + 1×1×C/r×G×K×K =(C²+CGK²)/r; 而传统卷积为K²C²,因为C一般会比G少得多得多,因此Involution参数量更少。
卷积核的运作:
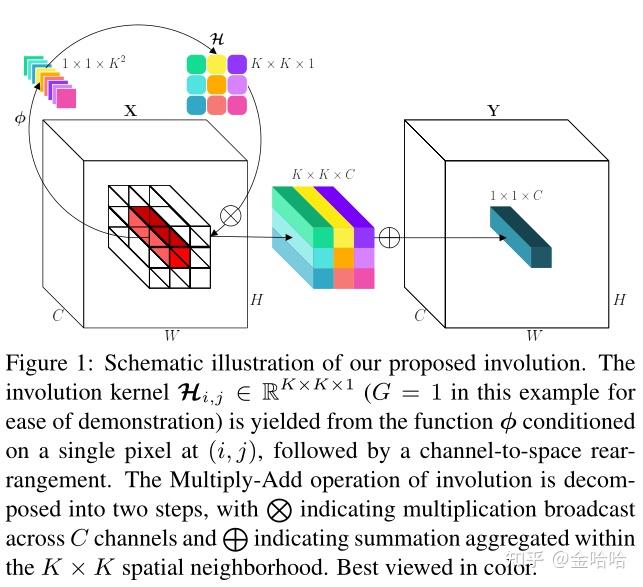
首先根据特征图上的点生成一个将特征图上的每一个点都unfold扩展为其K×K领域的大小,再与K×K大小的kernel进行multiply-add操作(卷积操作),也就是进行聚合,变为一个空间位置的输出特征点。(上图为假设G=1的情况)
整个involution的代码(包括生成与执行)
import torchimport torch.nn as nnclass Involution(nn.Module): def __init__(self, channels, kernel_size=7, stride=1, group_channels=16, reduction_ratio=4): super().__init__() assert not (channels % group_channels or channels % reduction_ratio) # in_c=out_c self.channels = channels self.kernel_size = kernel_size self.stride = stride # 每组多少个通道 self.group_channels = group_channels self.groups = channels // group_channels # reduce channels self.reduce = nn.Sequential( nn.Conv2d(channels, channels // reduction_ratio, 1), nn.BatchNorm2d(channels // reduction_ratio), nn.ReLU() ) # span channels self.span = nn.Conv2d( channels // reduction_ratio, self.groups * kernel_size ** 2, 1 ) self.down_sample = nn.AvgPool2d(stride) if stride != 1 else nn.Identity() self.unfold = nn.Unfold(kernel_size, padding=(kernel_size - 1) // 2, stride=stride) def forward(self, x): # Note that 'h', 'w' are height & width of the output feature. # generate involution kernel: (b,G*K*K,h,w) weight_matrix = self.span(self.reduce(self.down_sample(x))) b, _, h, w = weight_matrix.shape # unfold input: (b,C*K*K,h,w) x_unfolded = self.unfold(x) # (b,C*K*K,h,w)->(b,G,C//G,K*K,h,w) x_unfolded = x_unfolded.view(b, self.groups, self.group_channels, self.kernel_size ** 2, h, w) # (b,G*K*K,h,w) -> (b,G,1,K*K,h,w) weight_matrix = weight_matrix.view(b, self.groups, 1, self.kernel_size ** 2, h, w) # (b,G,C//G,h,w) mul_add = (weight_matrix * x_unfolded).sum(dim=3) # (b,C,h,w) out = mul_add.view(b, self.channels, h, w) return out
优势:
参数量和计算量更少
更有效地再广泛的空间范围内进行信息交互(能使用更大的卷积核)
在不同空间位置上仍具有知识共享/迁移能力:在生成Involution的时候用的是卷积,这实际上就潜在地引入了知识共享与迁移。
不需要位置编码
劣势:
无法灵活地改变通道数。需要改变通道数只能从外部通过池化技术进行
通道间的内部信息交换在一定程度上受影响
有待探究的地方:
对kernel生成方式的进一步探索;
结合NAS去搜索convolution-involution的混合结构
转载地址:http://ytfvi.baihongyu.com/